转自http://www.cublog.cn/u/13991/showart.php?id=96714
The History of GCC
1984年,Richard Stallman发起了自由软件运动,GNU (Gnu's Not Unix)项目应运而生,3年后,最初版的GCC横空出世,成为第一款可移植、可优化、支持ANSI C的开源C编译器。
GCC最初的全名是GNU C Compiler,之后,随着GCC支持的语言越来越多,它的名称变成了GNU Compiler Collection。
这里介绍的gcc是GCC的前端,C编译器.
警告信息
-Wall : 显示所有常用的编译警告信息。
-W : 显示更多的常用编译警告,如:变量未使用、一些逻辑错误。
-Wconversion : 警告隐式类型转换。
-Wshadow : 警告影子变量(在代码块中再次声明已声明的变量)
-Wcast-qual :警告指针修改了变量的修饰符。如:指针修改const变量。
-Wwrite-strings : 警告修改const字符串。
-Wtraditional : 警告ANSI编译器与传统C编译器有不同的解释。
-Werror : 即使只有警告信息,也不编译。(gcc默认:若只有警告信息,则进行编译,若有错误信息,则不编译)
C语言标准
你可以在gcc的命令行中通过指定选项来选择相应的C语言标准: 从传统c到最新的GNU扩展C. 默认情况下, gcc使用最新的GNU C扩展.
-ansi : 关闭GNU扩展中与ANSI C相抵触的部分。
-pedantic : 关闭所有的GNU扩展。
-std=c89 : 遵循C89标准
-std=c99 : 遵循C99标准
-std=traditional : 使用原始C
注意:后4个选项可以与-ansi结合使用,也可以单独使用。
可在gcc中使用大量GNU C扩展.
生成特定格式的文件
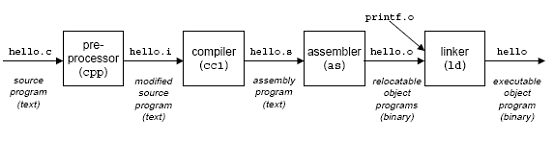
以hello.c为例子,可以设置选项生成hello.i, hello.s, hello.o以及最终的hello文件:
hello.c : 最初的源代码文件;
hello.i : 经过编译预处理的源代码;
hello.s : 汇编处理后的汇编代码;
hello.o : 编译后的目标文件,即含有最终编译出的机器码,但它里面所引用的其他文件中函数的内存位置尚未定义。
hello / a.out : 最终的可执行文件
(还有.a(静态库文件), .so(动态库文件), .s(汇编源文件)留待以后讨论)
| 如果你不通过-o指定生成可执行文件名,那么会默认生成a.out. 不指定生成文件名肯能覆盖你上次生成的a.out.
e.g.
$ gcc hello.c
在不给gcc传递任何参数的情况下, gcc执行默认的操作: 将源文件编译为目标文件--> 将目标文件连接为可执行文件(名为a.out) --> 删除目标文件.
-c生成.o文件时,默认生成与源代码的主干同名的.o文件。比如对应hello.c生成hello.o. 但也可在生成目标文件时指定目标文件名(注意同时要给出.o后缀): $ gcc -c -o demo.o demo.c
|
$ gcc -Wall -c hello.c : 生成hello.o
$ gcc -Wall -c -save-temps hello.c : 生成hello.i, hello.s, hello.o
注意-Wall 选项的使用场合:仅在涉及到编译(即会生成.o文件时,用-Wall)
多文件编译、连接
如果原文件分布于多个文件中:file1.c, file2,c
$ gcc -Wall file1.c file2.c -o name
若对其中一个文件作了修改,则可只重新编译该文件,再连接所有文件:
$ gcc -Wall -c file2.c
$ gcc file1.c file2.o -c name
注意:若编译器在命令行中从左向右顺序读取.o文件,则它们的出现顺序有限制:含有某函数定义的文件必须出现在含有调用该函数的文件之后。好在GCC无此限制。
编译预处理
以上述的hello.c为例, 要对它进行编译预备处理, 有两种方法: 在gcc中指定-E选项, 或直接调用cpp.gcc的编译预处理命令程序为cpp,比较新版本的gcc已经将cpp集成了,但仍提供了cpp命令. 可以直接调用cpp命令, 也可以在gcc中指定-E选项指定它只进行编译预处理.
$
gcc -E hello.c == $ cpp hello.c上述命令马上将预处理结果显示出来. 不利于观看. 可采用-c将预处理结果保存:
$
gcc -E -c hello.i hello.c == $ cpp -o hello.i hello.c注意, -c指定名称要给出".i"后缀.
另外, gcc针对编译预处理提供了一些选项:
(1) 除了直接在源代码中用 #define NAME来定义宏外,gcc可在命令行中定义宏:-DNAME(其中NAME为宏名), 也可对宏赋值: -DNAME=value 注意等号两边不能有空格! 由于宏扩展只是一个替换过程,也可以将value换成表达式,但要在两边加上双括号: -DNAME="statement"
e.g. $
gcc -Wall -DVALUE="2+2" tmp.c -o tmp如果不显示地赋值,如上例子,只给出:-DVALUE,gcc将使用默认值:1.
(2) 除了用户定义的宏外, 有一些宏是编译器自动定义的,它们以__开头,运行: $
cpp -dM /dev/null, 可以看到这些宏. 注意, 其中含有不以__开头的非ANSI宏,它们可以通过-ansi选项被禁止。
查看宏扩展
1, 运行 $
gcc -E test.c ,gcc对test.c进行编译预处理,并立马显示结果. (不执行编译) 2, 运行 $
gcc -c -save-temps test.c ,不光产生test.o,还产生test.i, test.s,前者是编译预处理结果, 后者是汇编结果.
利用Emacs查看编译预处理结果
针对含有编译预处理命令的代码,可以利用emacs方便地查看预处理结果,而不需执行编译,更为方便的是,可以只选取一段代码,而非整个文件:
1,选择想要查看的代码
2,C-c C-e (M-x c-macro-expand)
这样,就自动在一个名为"Macroexpansion"的buffer中显示pre-processed结果.
生成汇编代码
使用"-S"选项指定gcc生成以".s"为后缀的汇编代码:
$
gcc -S hello.c$
gcc -S -o hello.s hello.c生成汇编语言的格式取决于目标平台. 另外, 如果是多个.c文件, 那么针对每一个.c文件生成一个.s文件.
包含头文件
在程序中包含与连接库对应的头文件是很重要的方面,要使用库,就一定要能正确地引用头文件。一般在代码中通过#include引入头文件, 如果头文件位于系统默认的包含路径(/usr/includes), 则只需在#include中给出头文件的名字, 不需指定完整路径. 但若要包含的头文件位于系统默认包含路径之外, 则有其它的工作要做: 可以(在源文件中)同时指定头文件的全路径. 但考虑到可移植性,最好通过-I在调用gcc的编译命令中指定。
下面看这个求立方的小程序(阴影语句表示刚开始不存在):
#include
#include
int main(int argc, char *argv[])
{
double x = pow (2.0, 3.0);
printf("The cube of 2.0 is %f\n", x);
return 0;
} |
使用gcc-2.95来编译它(-lm选项在后面的连接选项中有介绍, 这里只讨论头文件的包含问题):
$ gcc-2.95 -Wall pow.c -lm -o pow_2.95
pow.c: In function `main':
pow.c:5: warning: implicit declaration of function `pow'
程序编译成功,但gcc给出警告: pow函数隐式声明。
$ ./pow_2.95
The cube of 2.0 is 1.000000
明显执行结果是错误的,在源程序中引入头文件(#include ),消除了错误。
不要忽略Warning信息!它可能预示着,程序虽然编译成功,但运行结果可能有错。故,起码加上"-Wall"编译选项!并尽量修正Warning警告。
|
搜索路径
首先要理解 #include和#include"file.h"的区别:
#include只在默认的系统包含路径搜索头文件
#include"file.h"首先在当前目录搜索头文件, 若头文件不位于当前目录, 则到系统默认的包含路径搜索头文件.
UNIX类系统默认的系统路径为:
头文件,包含路径: /usr/local/include/ or /usr/include/
库文件,连接路径: /usr/local/lib/ or /usr/lib/
对于标准c库(glibc或其它c库)的头文件, 我们可以直接在源文件中使用#include 来引入头文件.
如果要在源文件中引入自己的头文件, 就需要考虑下面的问题:
1, 如果使用非系统头文件, 头文件和源文件位于同一个目录, 如何引用头文件呢?
——我们可以简单地在源文件中使用 #include "file.h", gcc将当前目录的file.h引入到源文件. 如果你很固执, 仍想使用#include 语句, 可以在调用gcc时添加"-I."来将当前目录添加到系统包含路径. 细心的朋友可能会想到: 这样对引用其它头文件会不会有影响? 比如, #include之后紧接着一个#include, 它能正确引入math.h吗? 答案是: 没有影响. 仍然能正确引用math.h. 我的理解是: "-I."将当前目录作为包含路径的第一选择, 若在当前目录找不到头文件, 则在默认路径搜索头文件. 这实际上和#include"file.h"是一个意思.
2, 对于比较大型的工程, 会有许多用户自定义的头文件, 并且头文件和.c文件会位于不同的目录. 又该如何在.c文件中引用头文件呢?
—— 可以直接在.c文件中利用#include“/path/file.h", 通过指定头文件的路径(可以是绝对路径, 也可以是相对路径)来包含头文件. 但这明显降低了程序的可移植性. 在别的系统环境下编译可能会出现问题. 所以还是利用"-I"选项指定头文件完整的包含路径.
针对头文件比较多的情况, 最好把它们统一放在一个目录中, 比如~/project/include. 这样就不需为不同的头文件指定不同的路径. 如果你嫌每次输入这么多选项太麻烦, 你可以通过设置环境变量来添加路径:
$ C_INCLUDE_PATH=/opt/gdbm-1.8.3/include
$ export C_INCLUDE_PATH
$ LIBRART_PATH=/opt/gdbm-1.8.3/lib
$ export LIBRART_PATH
可一次指定多个搜索路径,":"用于分隔它们,"."表示当前路径,如:
$ C_INCLUDE_PATH=.:/opt/gdbm-1.8.3/include:/net/include
$ LIBRARY_PATH=.:/opt/gdbm-1.8.3/lib:/net/lib
(可以添加多个路径,路径之间用:相隔,.代表当前目录,若.在最前头,也可省略)
当然,若想永久地添加这些路径,可以在.bash_profile中添加上述语句.
|
3, 还有一个比较猥琐的办法: 系统默认的包含路径不是/usr/include或/usr/local/include么? 我把自己的头文件拷贝到其中的一个目录, 不就可以了么? 的确可以这样, 如果你只想在你自己的机器上编译运行这个程序的话 .
.
前面介绍了三种添加搜索路径的方法,如果这三种方法一起使用,优先级如何呢?
命令行设置 > 环境变量设置 > 系统默认
与外部库连接
前面介绍了如何包含头文件. 而头文件和库是息息相关的, 使用库时, 要在源代码中包含适当的头文件,这样才能声明库中函数的原型(发布库时, 就需要给出相应的头文件).
和包含路径一样, 系统也有默认的连接路径:
头文件,包含路径: /usr/local/include/ or /usr/include/库文件,连接路径: /usr/local/lib/ or /usr/lib/ 同样地, 我们想要使用某个库里的函数, 必须将这个库连接到使用那些函数的程序中.
有一个例外: libc.a或libc.so (C标准库,它包含了ANSI C所定义的C函数)是不需要你显式连接的, 所有的C程序在运行时都会自动加载c标准库.
|
除了C标准库之外的库称之为"外部库", 它可能是别人提供给你的, 也可能是你自己创建的(后面有介绍如何创建库的内容).
外部库有两种:(1)静态连接库lib.a
(2)共享连接库lib.so
两者的共同点:
.a, .so都是.o目标文件的集合,这些目标文件中含有一些函数的定义(机器码),而这些函数将在连接时会被最终的可执行文件用到。
两者的区别:
静态库.a : 当程序与静态库连接时,库中目标文件所含的所有将被程序使用的函数的机器码被copy到最终的可执行文件中. 静态库有个缺点: 占用磁盘和内存空间. 静态库会被添加到和它连接的每个程序中, 而且这些程序运行时, 都会被加载到内存中. 无形中又多消耗了更多的内存空间.
共享库.so : 与共享库连接的可执行文件只包含它需要的函数的引用表,而不是所有的函数代码,只有在程序执行时, 那些需要的函数代码才被拷贝到内存中, 这样就使可执行文件比较小, 节省磁盘空间(更进一步,操作系统使用虚拟内存,使得一份共享库驻留在内存中被多个程序使用).共享库还有个优点: 若库本身被更新, 不需要重新编译与 它连接的源程序。
静态库
下面我们来看一个简单的例子,计算2.0的平方根(假设文件名为sqrt.c):
#include
#include
int
main (void)
{
double x = sqrt (2.0);
printf ("The square root of 2.0 is %f\n", x);
return 0;
}
|
用gcc将它编译为可执行文件:
$ gcc -Wall sqrt.c -o sqrt
编译成功,没有任何警告或错误信息。执行结果也正确。
$ ./sqrt
The square root of 2.0 is 1.414214
下面我们来看看刚才使用的gcc版本:
$ gcc --version
gcc (GCC) 4.0.2 20050808 (prerelease) (Ubuntu 4.0.1-4ubuntu9)
现在我用2.95版的gcc把sqrt.c再编译一次:
$ gcc-2.95 -Wall sqrt.c -o sqrt_2.95
/tmp/ccVBJd2H.o: In function `main':
sqrt.c:(.text+0x16): undefined reference to `sqrt'
collect2: ld returned 1 exit status
编 译器会给出上述错误信息,这是因为sqrt函数不能与外部数学库"libm.a"相连。sqrt函数没有在程序中定义,也不存在于默认C库 "libc.a"中,如果用gcc-2.95,应该显式地选择连接库。上述出错信息中的"/tmp/ccVBJd2H.o"是gcc创造的临时目标文件, 用作连接时用。
使用下列的命令可以成功编译:
$ gcc-2.95 -Wall sqrt.c /usr/lib/libm.a -o sqrt_2.95
它告知gcc:在编译sqrt.c时,加入位于/usr/lib中的libm.a库(C数学库)。
C库文件默认位于/usr/lib, /usr/local/lib系统目录中; gcc默认地从/usr/local/lib, /usr/lib中搜索库文件。(在我的Ubuntu系统中,C库文件位于/urs/lib中。
|
这里还要注意连接顺序的问题,比如上述命令,如果我改成:
$ gcc-2.95 -Wall /usr/lib/libm.a sqrt.c -o sqrt_2.95
gcc会给出出错信息:
/tmp/cc6b3bIa.o: In function `main':
sqrt.c:(.text+0x16): undefined reference to `sqrt'
collect2: ld returned 1 exit status
正如读取目标文件的顺序,gcc也在命令行中从左向右读取库文件——任何包含某函数定义的库文件必须位于调用该函数的目标文件之后!
指定库文件的绝对路径比较繁琐,有一种简化方法,相对于上述命令,可以用下面的命令来替代:
$ gcc-2.95 -Wall sqrt.c -lm -o sqrt_2.95
其中的"-l"表示与库文件连接,"m"代表"libm.a"中的m。一般而言,"-lNAME"选项会使gcc将目标文件与名为"libNAME.a"的库文件相连。(这里假设使用默认目录中的库,对于其他目录中的库文件,参考后面的“搜索路径”。)
上面所提到的"libm.a"就是静态库文件,所有静态库文件的扩展名都是.a!
$ whereis libm.a
libm: /usr/lib/libm.a /usr/lib/libm.so
正如前面所说,默认的库文件位于/usr/lib/或/usr/local/lib/目录中。其中,libm.a是静态库文件,libm.so是后面会介绍的动态共享库文件。
如果调用的函数都包含在libc.a中(C标准库被包含在/usr/lib/libc.a中,它包含了ANSI C所定义的C函数)。那么没有必要显式指定libc.a:所有的C程序运行时都自动包含了C标准库!(试试 $ gcc-2.95 -Wall hello.c -o hello)。
共享库
正因为共享库的优点,如果系统中存在.so库,gcc默认使用共享库(在/usr/lib/目录中,库文件以共享和静态两种版本存在)。
运行:$ gcc -Wall -L. hello.c -lNAME -o hello
gcc先检查是否有替代的libNAME.so库可用。
正如前面所说,共享库以.so为扩展名(so == shared object)。
那么,如果不想用共享库,而只用静态库呢?可以加上 -static选项
$ gcc -Wall -static hello.c -lNAME -o hello
它等价于:
$ gcc -Wall hello.c libNAME.a -o hello
$ gcc-2.95 -Wall sqrt.c -static -lm -o sqrt_2.95_static
$ gcc-2.95 -Wall sqrt.c -lm -o sqrt_2.95_default
$ gcc-2.95 -Wall sqrt.c /usr/lib/libm.a -o sqrt_2.95_a
$ gcc-2.95 -Wall sqrt.c /usr/lib/libm.so -o sqrt_2.95_so
$ ls -l sqrt*
-rwxr-xr-x 1 zp zp 21076 2006-04-25 14:52 sqrt_2.95_a
-rwxr-xr-x 1 zp zp 7604 2006-04-25 14:52 sqrt_2.95_default
-rwxr-xr-x 1 zp zp 7604 2006-04-25 14:52 sqrt_2.95_so
-rwxr-xr-x 1 zp zp 487393 2006-04-25 14:52 sqrt_2.95_static
上述用四种方式编译sqrt.c,并比较了可执行文件的大小。奇怪的是,-static -lm 和 /lib/libm.a为什么有区别?有知其原因着,恳请指明,在此谢谢了! :)
如果libNAME.a在当前目录,应执行下面的命令:
$ gcc -Wall -L. hello.c -lNAME -o hello
-L.表示将当前目录加到连接路径。
利用GNU archiver创建库
$ ar cr libhello.a hello_fn.o by_fn.o
从hello_fn.o和by_fn.o创建libihello.a,其中cr表示:creat & replace
$ ar t libhello.a
列出libhello.a中的内容,t == table
(也可创建libhello.so)
关于创建库的详细介绍,可参考本blog的GNU binutils笔记
调试
一般地,可执行文件中是不包含任何对源代码的参考的,而debugger要工作,就要知道目标文件/可执行文件中的机器码对应的源代码的信息(如:哪条语 句、函数名、变量名...). debugger工作原理:将函数名、变量名,对它们的引用,将所有这些对象对应的代码行号储存到目标文件或可执行文件的符 号表中。
GCC提供-g选项,将调试信息加入到目标文件或可执行文件中。
$ gcc -Wall -g hello.c -o hello
注意:若发生了段错误,但没有core dump,是由于系统禁止core文件的生成!
$ ulimit -c ,若显示为0,则系统禁止了core dump
解决方法:
$ ulimit -c unlimited (只对当前shell进程有效)
或在~/.bashrc 的最后加入: ulimit -c unlimited (一劳永逸)
优化
GCC具有优化代码的功能,代码的优化是一项比较复杂的工作,它可归为:源代码级优化、速度与空间的权衡、执行代码的调度。
GCC提供了下列优化选项:
-O0 : 默认不优化(若要生成调试信息,最好不优化)
-O1 : 简单优化,不进行速度与空间的权衡优化;
-O2 : 进一步的优化,包括了调度。(若要优化,该选项最适合,它是GNU发布软件的默认优化级别;
-O3 : 鸡肋,兴许使程序速度更慢;
-funroll-loops : 展开循环,会使可执行文件增大,而速度是否增加取决于特定环境;
-Os : 生成最小执行文件;
一般来说,调试时不优化,一般的优化选项用-O2(gcc允许-g与-O2联用,这也是GNU软件包发布的默认选项),embedded可以考虑-Os。
注意:此处为O!(非0或小写的o,-o是指定可执行文件名)。
检验优化结果的方法:$ time ./prog
time测量指定程序的执行时间,结果由三部分组成:
real : 进程总的执行时间, 它和系统负载有关(包括了进程调度,切换的时间)
user: 被测量进程中用户指令的执行时间
sys : 被测量进程中内核代用户指令执行的时间
user和sys的和被称为CPU时间.
注意:对代码的优化可能会引发警告信息,移出警告的办法不是关闭优化,而是调整代码。
转自 http://www.cublog.cn/u/13991/showart.php?id=96714